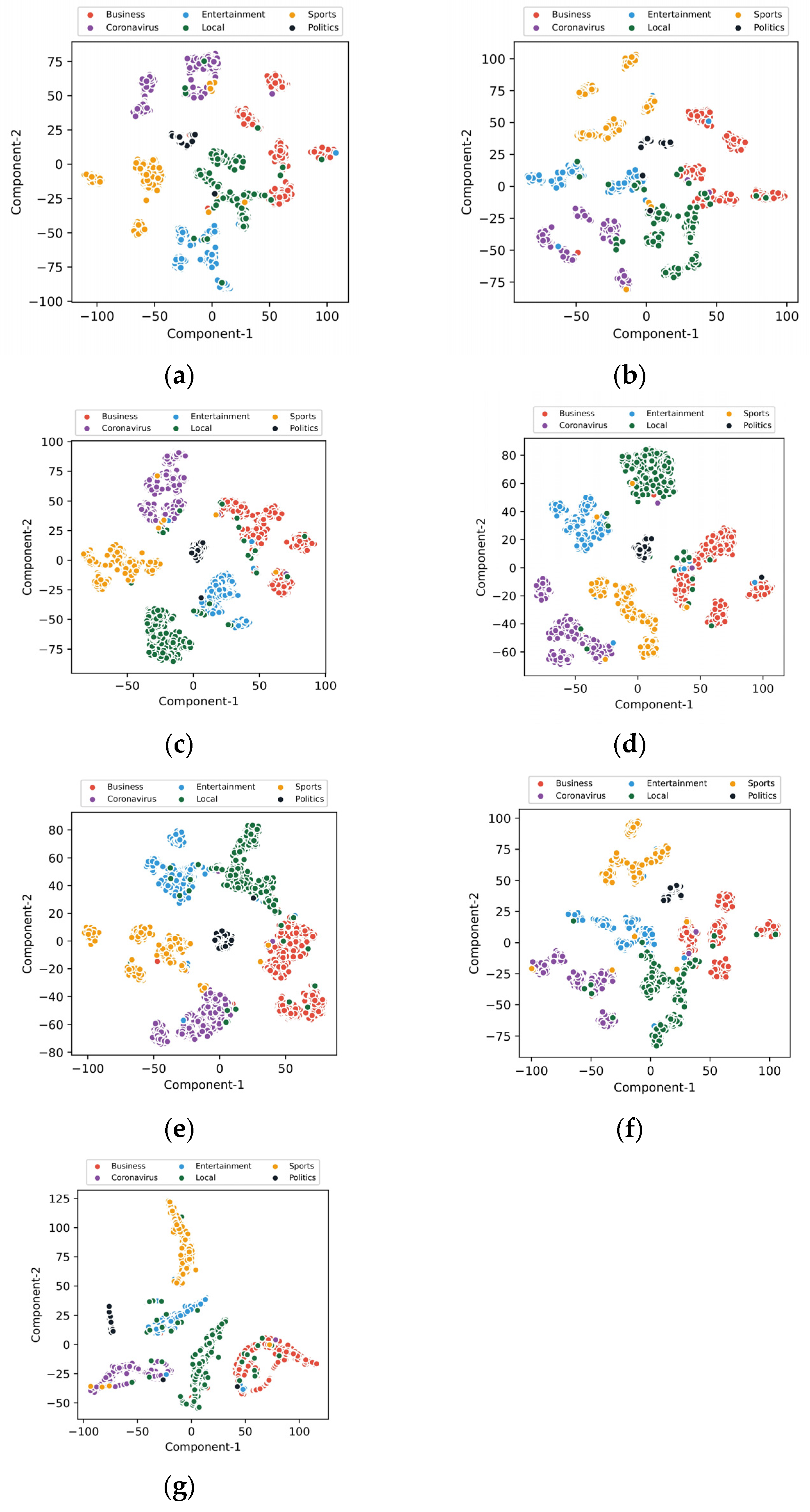
Despite a few attempts to automatically crawl Ewe text from online news portals and magazines, the African Ewe language remains underdeveloped despite its rich morphology and complex "unique" structure. This is due to the poor quality, unbalanced, and religious-based nature of the crawled Ewe texts, thus making it challenging to preprocess and perform any NLP task with current transformer-based language models. In this study, we present a well-preprocessed Ewe dataset for low-resource text classification to the research community. Additionally, we have developed an Ewe-based word embedding to leverage the low-resource semantic representation. Finally, we have fine-tuned seven transformer-based models, namely BERT-based (cased and uncased), DistilBERT-based (cased and uncased), RoBERTa, DistilRoBERTa, and DeBERTa, using the preprocessed Ewe dataset that we have proposed. Extensive experiments indicate that the fine-tuned BERT-base-cased model outperforms all baseline models with an accuracy of 0.972, precision of 0.969, recall of 0.970, loss score of 0.021, and an F1-score of 0.970. This performance demonstrates the model’s ability to comprehend the low-resourced Ewe semantic representation compared to all other models, thus setting the fine-tuned BERT-based model as the benchmark for the proposed Ewe dataset.

Human Body Systems Flip Book {FREE} - CURRICULUM CASTLE
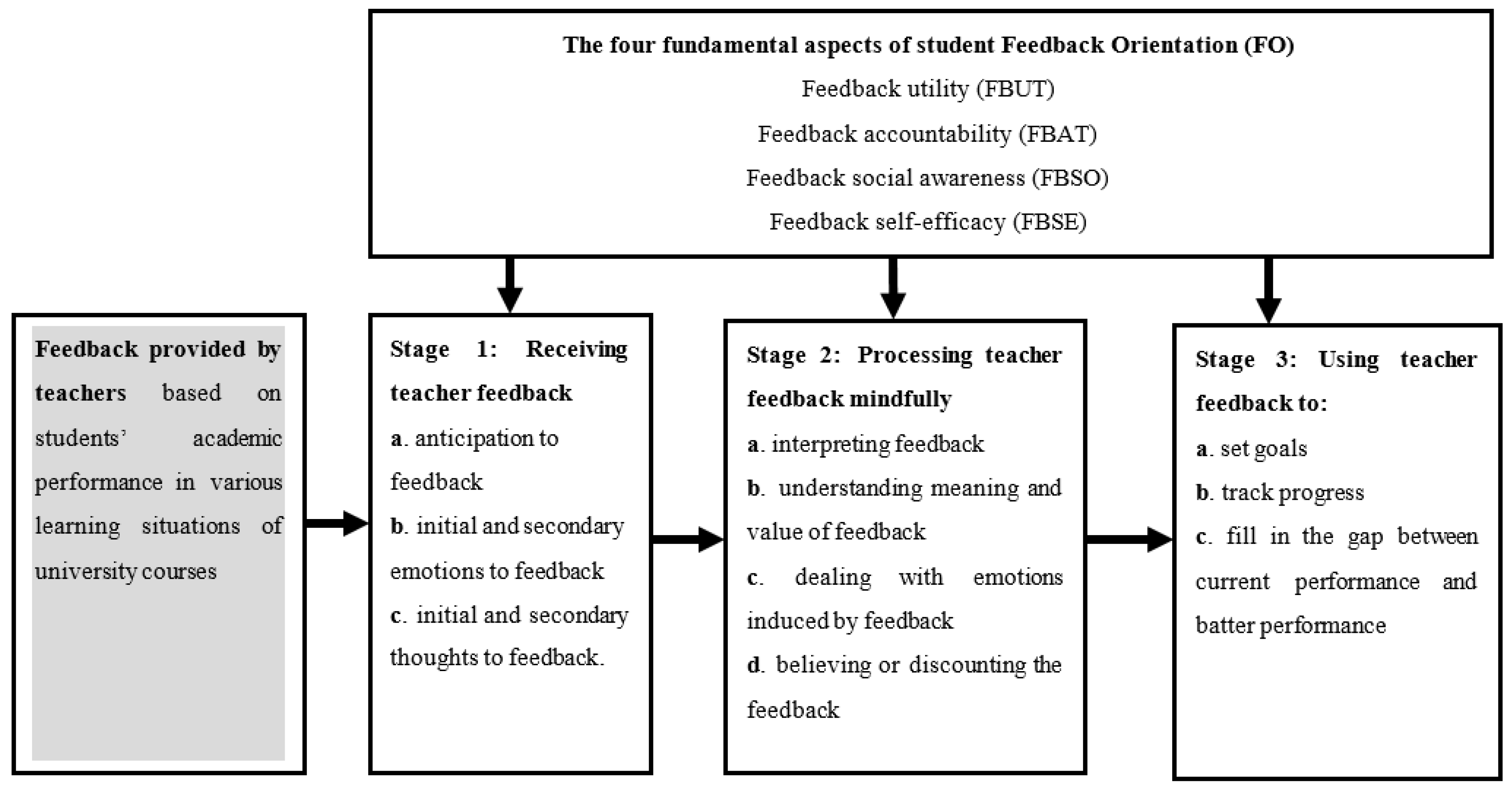
Systems, Free Full-Text

Systems, Free Full-Text
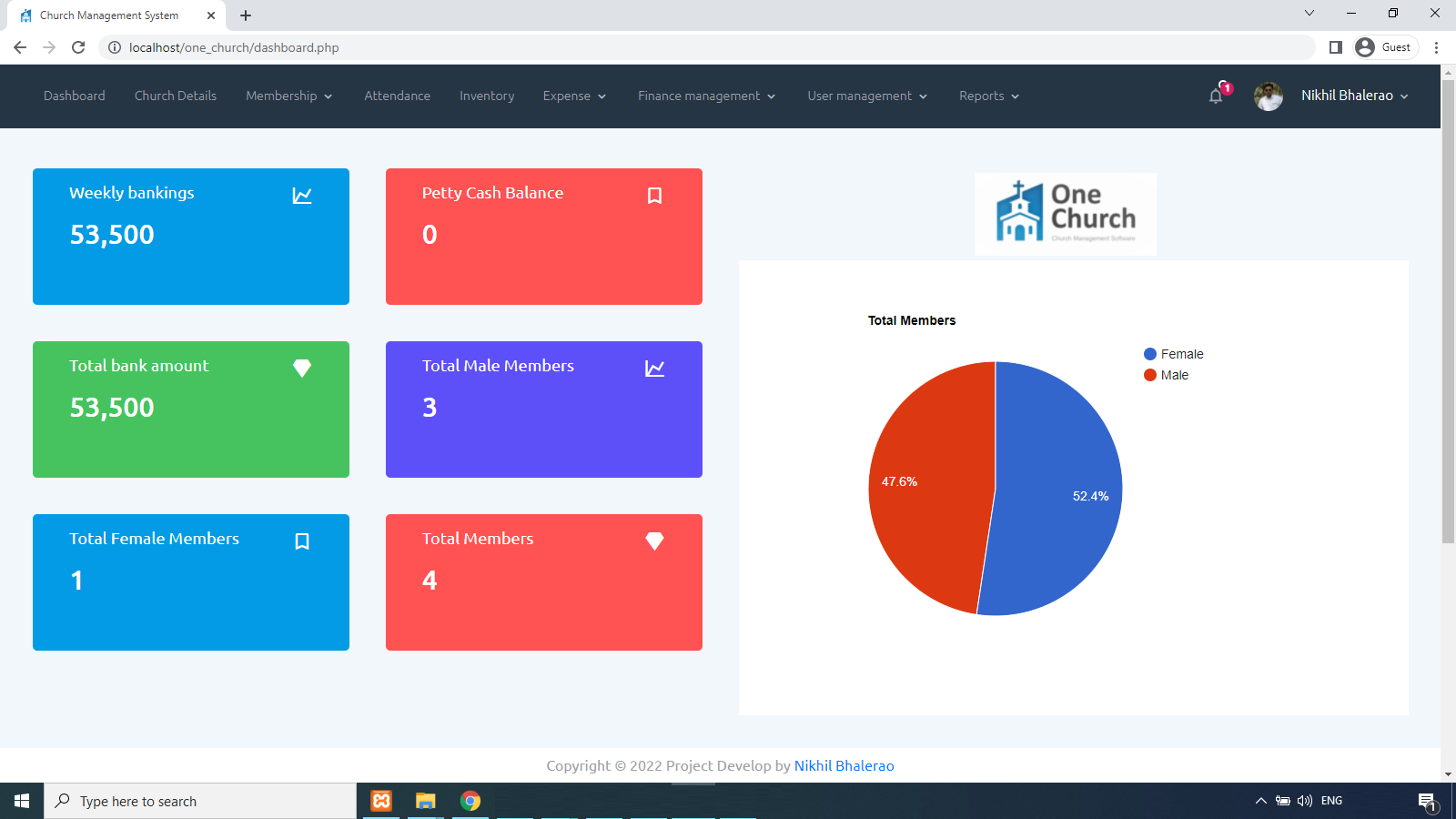
Church Management Software Source Code Free Download Full Version

Did you know IBM Technology Zone is available to Business Partners for free?

International Scientific Conference “Resilience by Technology and
Brazil Fertile Ground for Free-to-Play Games - Interpret, free
WIRE definition in the Cambridge English Dictionary, Wire

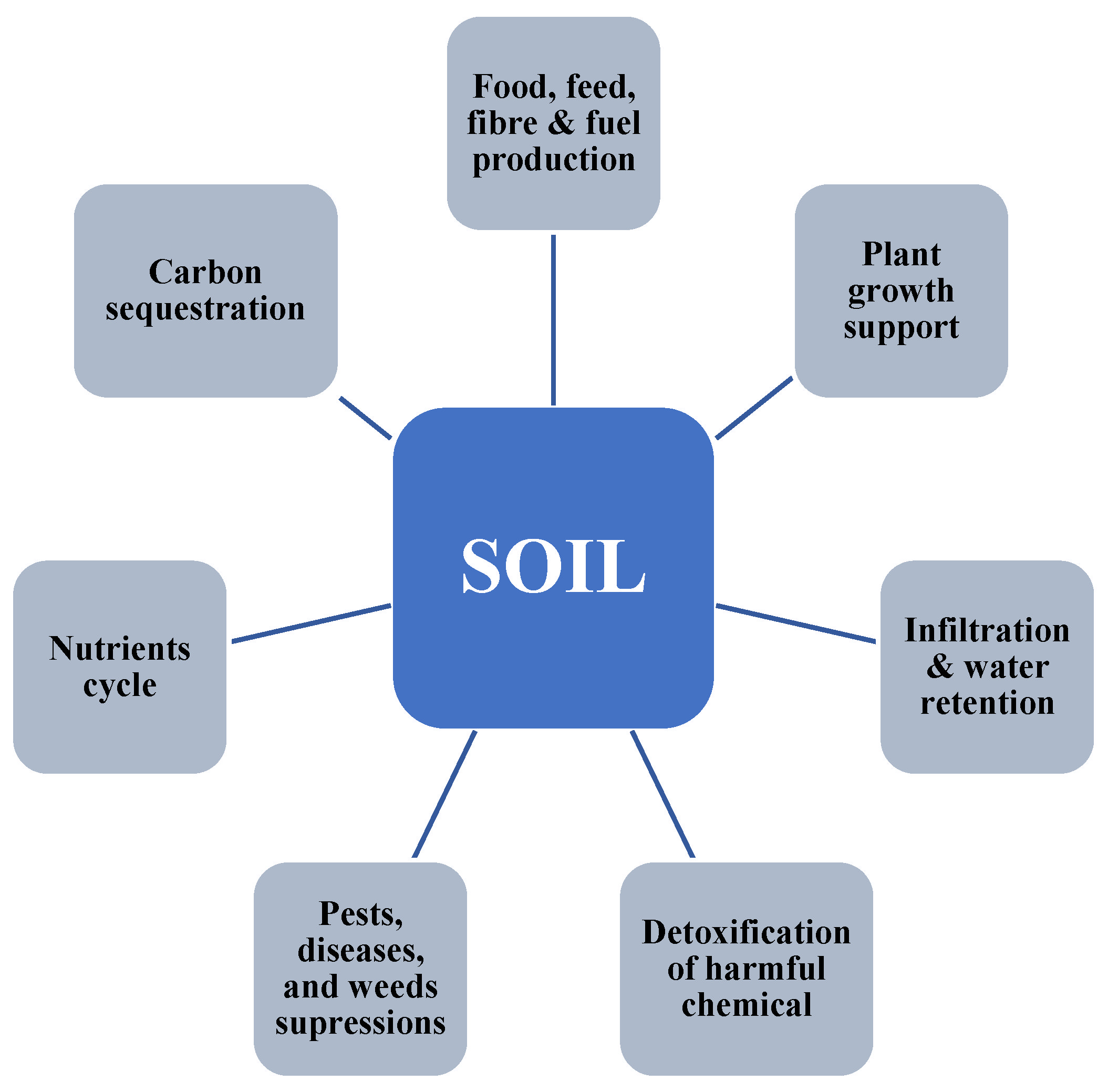
Soil Systems, Free Full-Text











