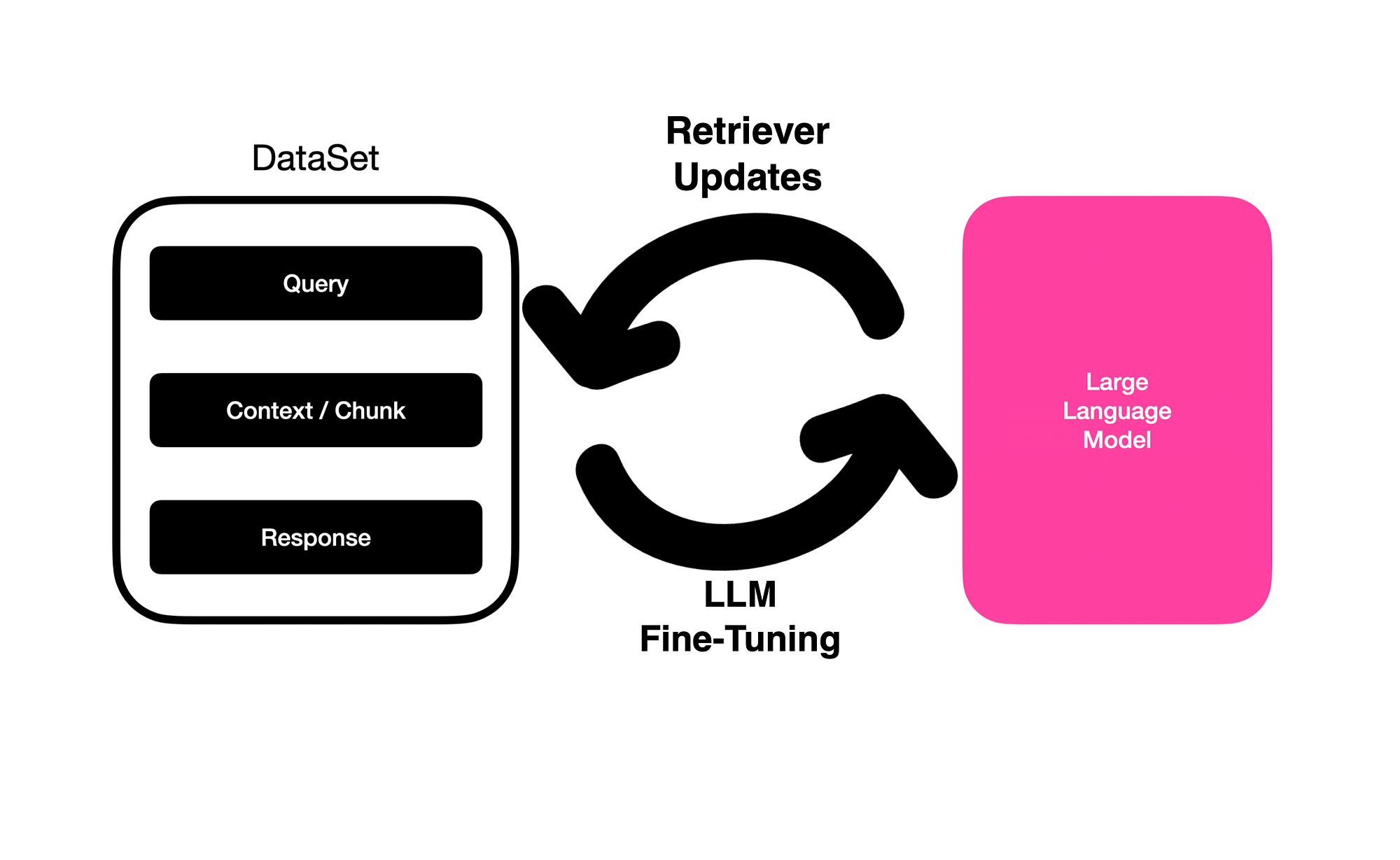
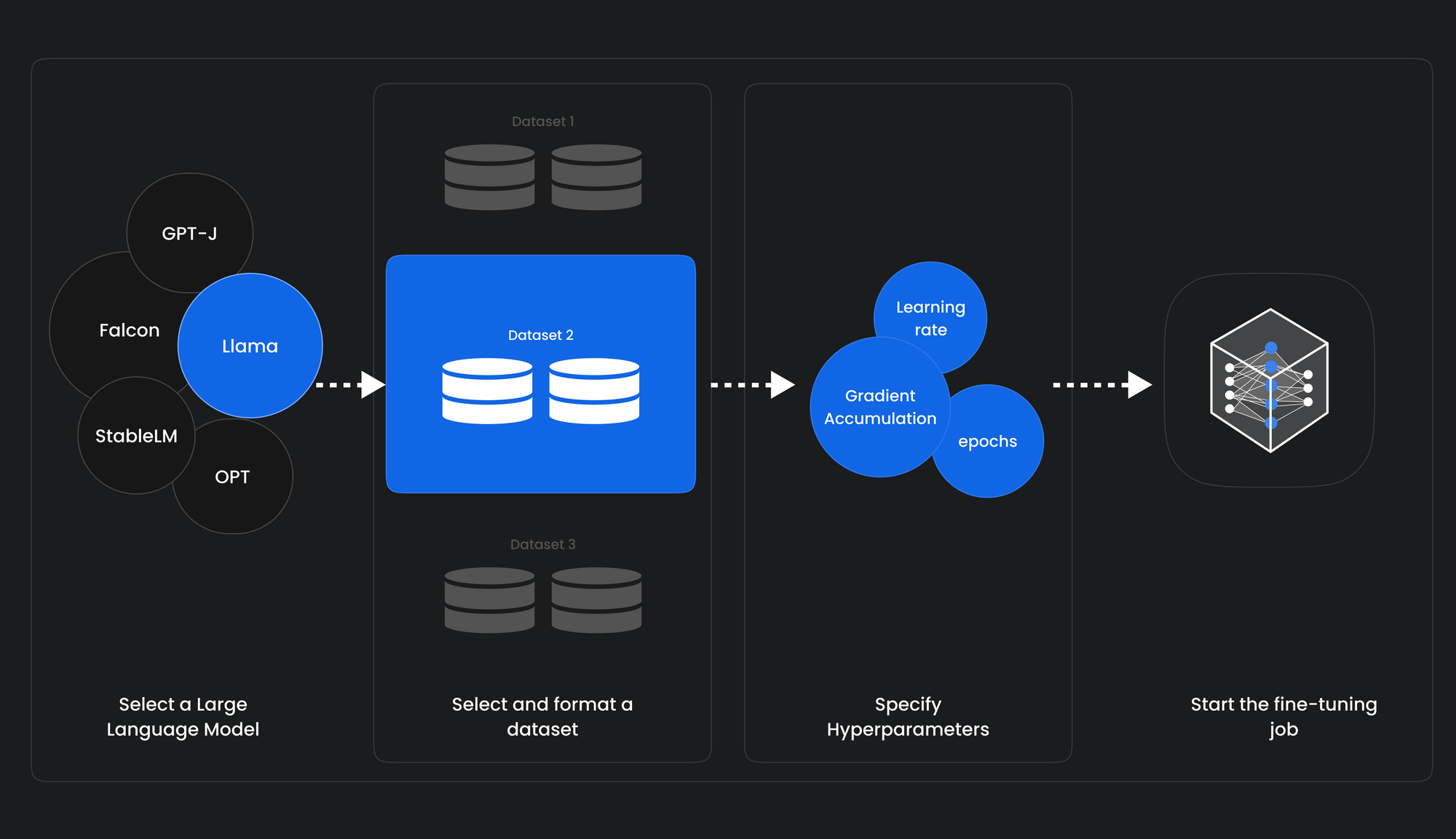
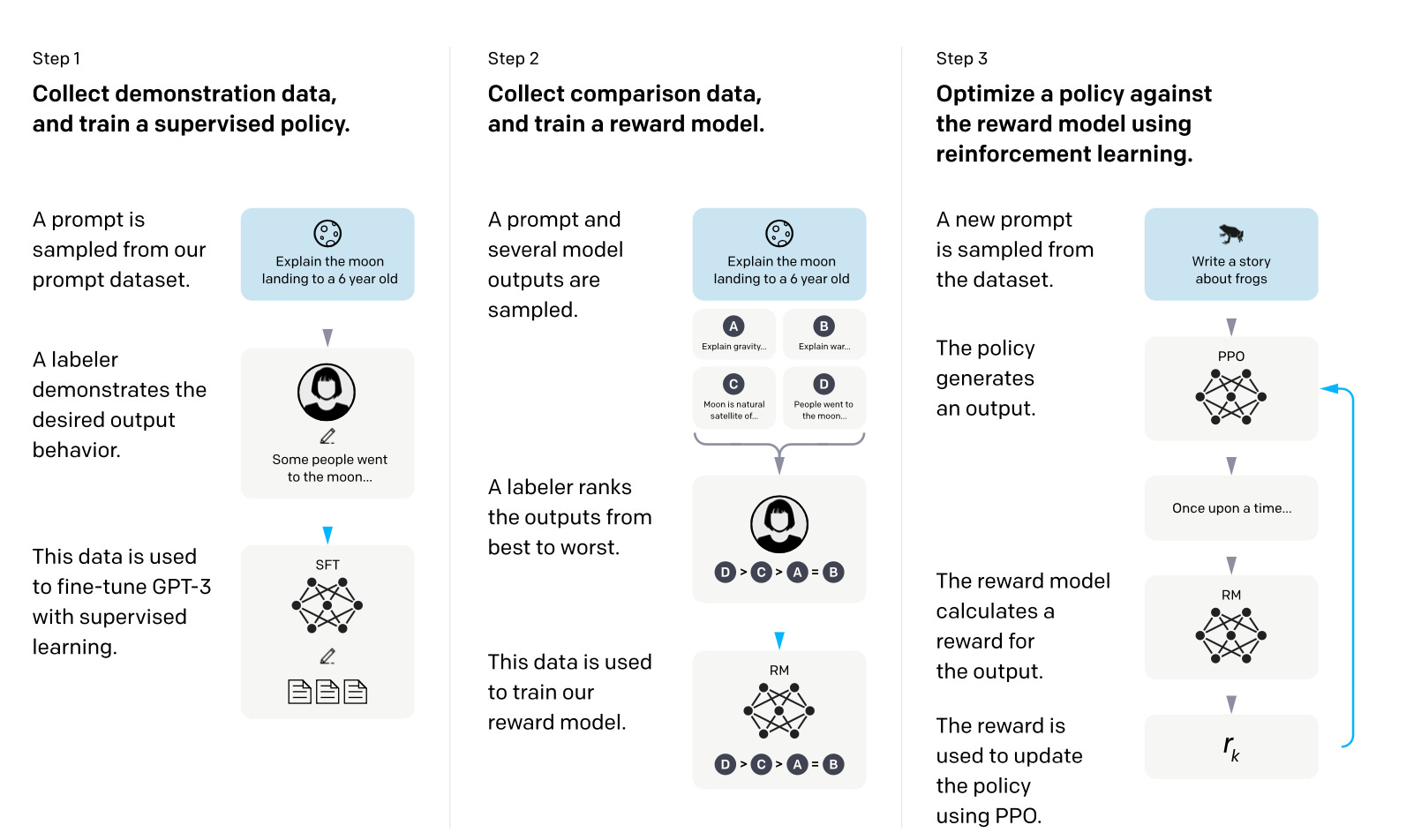
The LLM Triad: Tune, Prompt, Reward - Gradient Flow
5 (121) · $ 5.99 · In stock

As language models become increasingly common, it becomes crucial to employ a broad set of strategies and tools in order to fully unlock their potential. Foremost among these strategies is prompt engineering, which involves the careful selection and arrangement of words within a prompt or query in order to guide the model towards producing theContinue reading "The LLM Triad: Tune, Prompt, Reward"

Understanding RLHF for LLMs

Understanding RLHF for LLMs
Everything You Need To Know About Fine Tuning of LLMs
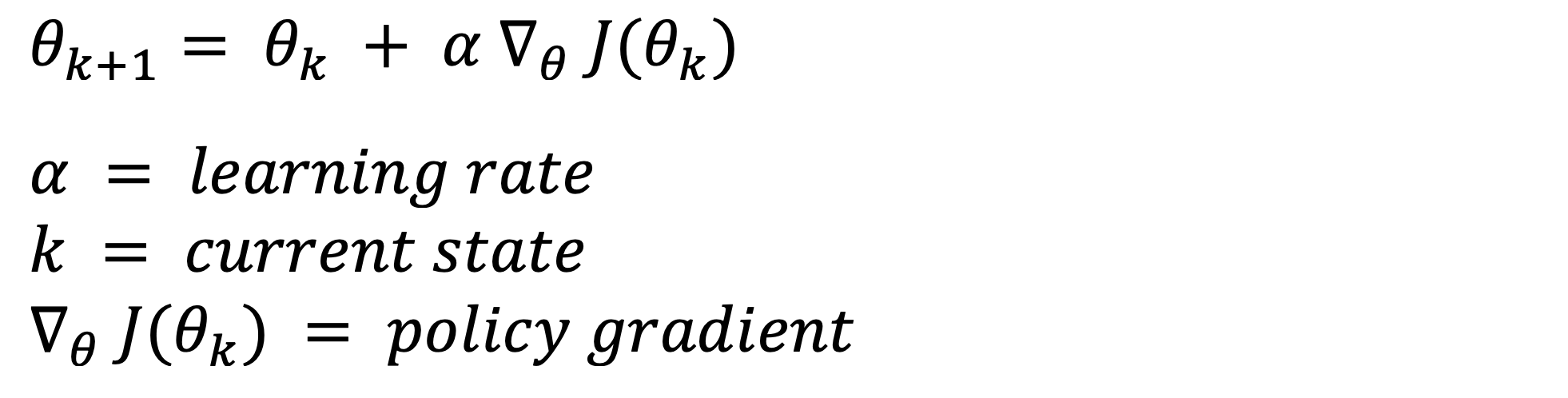
Understanding RLHF for LLMs

Reinforcement Learning from Human Feedback (RLHF), by kanika adik

Paper page - Directly Fine-Tuning Diffusion Models on Differentiable Rewards

Damien Benveniste, PhD on LinkedIn: Fine-tuning an LLM may not be as trivial as we may think! Depending on…

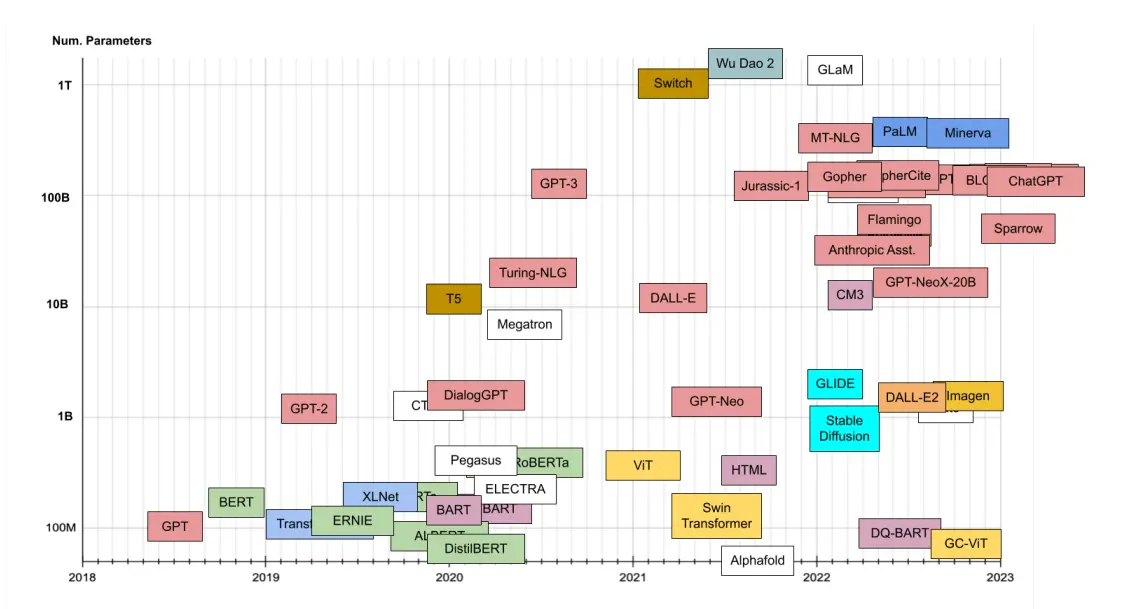
Open-Source LLM Explained: A Beginner's Journey Through Large Language Models, by ByFintech @ AI4Finance Foundation

Introduction to LLM Model Fine Tuning

Maximizing Rewards with Policy Gradient Methods and Monte Carlo Reinforcement Learning- Part 2(Reinforcement Learning), by Ankush k Singal, AI Artistry